In part one of this guide we discussed data science and the field as a whole, and now we'll focus on machine learning. In part three we'll touch on big data.
To recap, it's easiest to understand this whole field as a diagram:
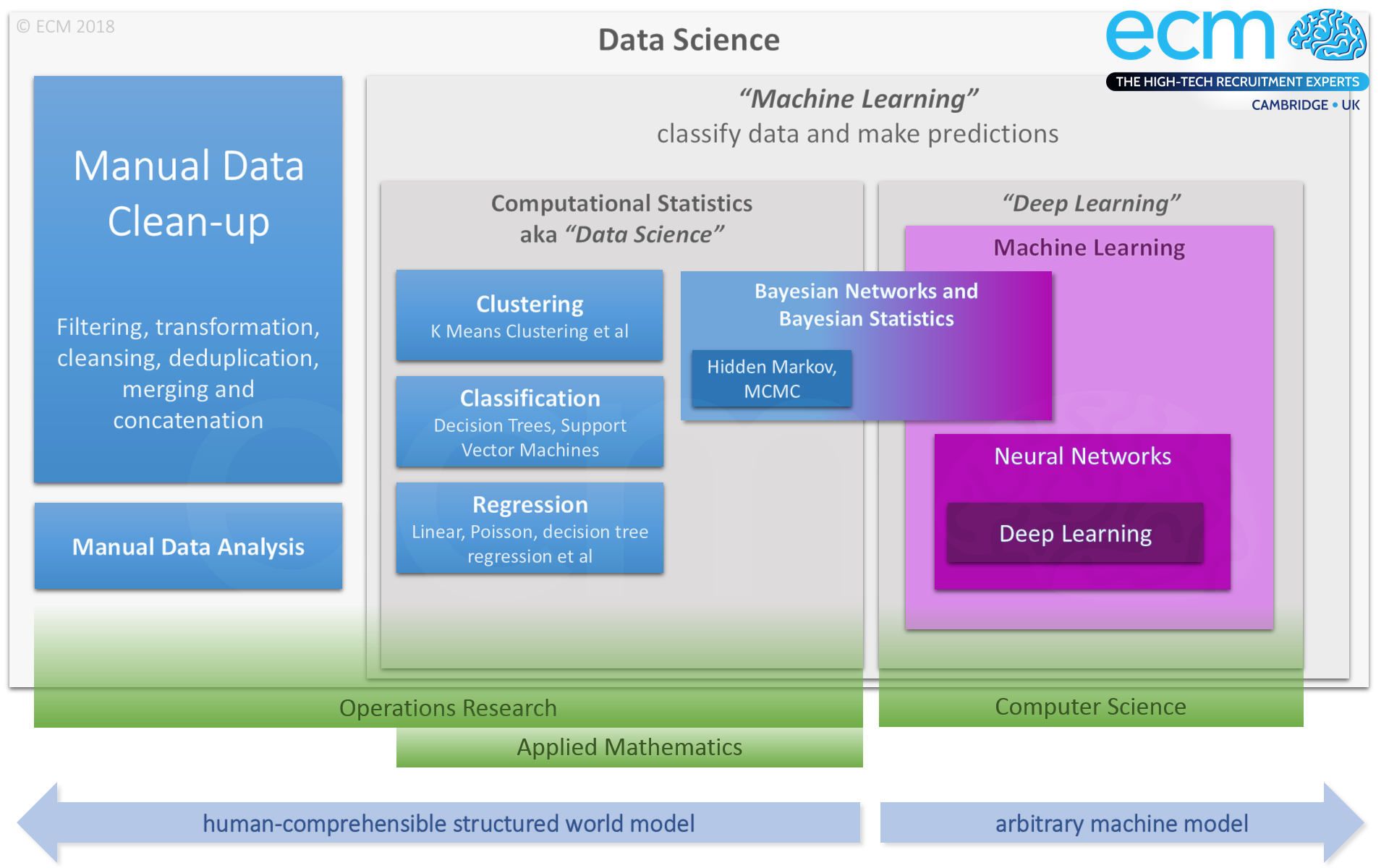
(A larger version of this diagram is available for download. Depending on your web browser, clicking the link may save it to your Downloads without telling you it's done so.)
As in part one when we discussed data science, quoted terms indicate common, broad usage, and unquoted terms more technical from particular perspectives - both are valid usages, of course.
Machine Learning: The Broad View
To many professionals in data science, the point at which “machine learning” kicks in is the point at which they no longer have as direct influence over the data, the construction of the model, and statistical processes being used to analyse it: the machine is now directing the work. Some also refer to this as “deep learning”. Both terms refer to the increasing degree to which the process is a “black box” from an analysist’s or statistician’s point of view, rather than to the computer science definition of particular terms.
To some, techniques which are seeking numerical solutions through various applications of Bayes’ theorem also fall into this category (even though to purists the area of Bayesian statistics is simply a subset of statistics paying attention to conditional probabilities which are intentionally biased by foreknowledge of particular circumstance). Markov Chain Monte Carlo, or MCMC – being an often computational process which, like many forms of numerical solution, is iterated until the answer is considered a close enough approximation – has enough parallels with other machine-driven processes (for example, the integration loop required for physics simulation) to further encourage this viewpoint.
To these same professionals there is less of a distinction between these approaches and that of machine learning as computer science sees it. This is a key distinction when looking at opportunities in this field, since the methods and requirements applied to similar-sounding areas is very different from a practitioner’s perspective, and candidates’ backgrounds are often different.
Machine Learning:
The Computer Science View
From a computer scientist’s point of view, machine learning is a particular application of certain kinds of AI techniques which endeavour to give machine itself the ability to reason about a particular problem domain. In this narrower, classical definition some forms of computational statistics would not qualify as machine learning. With these, not only is the machine applying only the specific processes it’s been told to apply (and the data model and processes themselves can still reasonably be both understood and intuitively performed by a person) but the machine’s process does not change as a result of the activities it carries out, except through human intervention. In short, the machine doesn’t “learn” anything from its work.
It is worth noting that some, even many, computer scientists and programmers encourage expanding the classical definition of machine learning to more closely fit the broad, popular view; but one should be aware that this is a relatively recent development, and so some uses of the term are not this inclusive.
Classical machine learning is distinguished from simple computation by one key factor, which is that the same process applied on a dataset one week may well (indeed, ideally will) give different results once other data have also passed through this process, and this is true without human intervention. The machine adjusts its model as it goes, as in a sense a human would. This tends to have the side effect that the model the machine builds is truly a black box; it “makes sense” only to the machine, and if inspected by the programmer or data scientist, may not appear rational or comprehensible without first inspecting all the data which led to the derivation of this model by the machine’s algorithms, appearing as it will to be a series of connections and weightings of seemingly arbitrary complexity.
Image processing and natural language processing are two common applications of machine learning, though both can and do employ conventional computational techniques as well as potentially machine learning.
Neural networks (or more strictly, artificial neural networks) are one very well established kind of machine learning system. They bear little resemblance to a biological brain, so the reuse of terminology shouldn’t be taken to imply any more than superficial connection. Broadly speaking an artificial neural network is a web of small interconnected functions, and they share not only data but are able to influence each other by propagating elements of their results and/or decision-making. The network is greater than the sum of its parts in demonstrable ways; it is not truly thinking, nor does it understand anything about the data or domain in which it’s working (since it’s not a mind; it’s a program made up of simple data processing instructions), but it can evolve its algorithm if not its understanding.
It may be controversial to say so, but there are computer scientists who might claim that the field of neural networks has not in itself drastically changed in the last forty years; instead, as with most disciplines, successive research has built on previous results in an incremental rather than transformative way. This has a major upside for those who studied neural networks earlier in their career, in that much of their knowledge is still applicable.
Some of the greatest and most promising recent advances in neural networks have come through such evolution rather than revolution; deep learning, for example, applies many layers of neural network to the problem in a certain way.
A Career in Machine Learning
Whichever branch of machine learning interests you, a career in machine learning often implies a career in software development (but see also A Career As A Data Scientist!). As a developer in this field, you’ll need a strong mathematical background, especially including statistics, and very likely a bachelor’s degree in computer science as well as further postgraduate or doctoral studies in machine learning specifically.
You should enjoy mathematics, programming and working closely with data. You will need to be a prolific programmer. Whilst some positions will be engaged in more research or R&D activities, it’s very likely these are about bringing a software system up to date with the latest research occurring at academic institutions (though some valuable research has come out of commercial endeavours and collaborations). There will be a lot of implementation work, and working for a commercial company, you’ll still need the core attributes that would make you a good software developer anywhere.
One caveat is that the number of people interested in getting into this field vastly outweigh the number of positions available; and as a result, opportunities can tend to favour people who really understand it in depth, and can lead the team or the research, rather than learn from it. (A counterpoint to this, though, is that companies are capitalising on people’s interest, and hence offering interesting data science jobs under the banner of machine learning; so if both areas interest you, a broader selection of opportunities may be available.)
It’s also worth considering that in order to work as a developer in machine learning, you’ll have to fundamentally enjoy the process of engineering great software with other smart people; and if you do, there are a lot of other great opportunities out there in the software industry, doing arguably equally interesting things, and still requiring the same degree of intelligence and application. We recommend, as you might expect, speaking with a good recruiter without bias towards particular companies or openings, to give you an idea of what opportunities may excite you.
Register with ECM Jobs in Machine Learning
Continue reading about big data in part three.


